Predicting Advertising Recall from Brain Signals
My M.Sc. thesis at Politecnico di Milano, I built a machine learning pipeline that predicts whether a TV advertisement will be remembered - before it ever airs - using EEG brain signals recorded from viewers.
Published March 2026
Problem
Billions Spent, No Reliable Way to Know What Sticks
Every year, companies pour enormous budgets into TV advertising, in Italy alone, around €9.6 billion was spent in 2025, with roughly 40% going to linear television. Yet after all that investment, there is still no reliable, objective method to know — before a campaign launches — whether viewers will actually remember the ad.
The traditional tools?
- Surveys.
- Focus groups.
- Post-exposure questionnaires.
These methods capture what people consciously recall and report, which is a pretty unreliable signal. People rationalize, forget, and are influenced by the order in which they answer questions. They tell you what they think you want to hear.
This is not a marginal inefficiency. A poorly memorable ad on national television is a multi-million-euro mistake and it could have been caught earlier.
So the question that motivated my thesis was simple to state, harder to answer:
And beyond just "can we", the more interesting engineering question:
Neuromarketing Meets Machine Learning
Let's briefly unpack the problem. We have a dataset of EEG recordings from participants who watched TV ads, along with labels indicating whether they recalled the ad afterward.
EEG (electroencephalography) measures electrical activity on the scalp — tiny voltage fluctuations that reflect what's happening in the brain in real time. Unlike surveys, EEG doesn't filter through conscious reflection. It captures neural responses millisecond by millisecond as someone watches a video.
For marketing, this is valuable. Attention, emotional engagement, and memory encoding all leave measurable traces in EEG signals. Key markers include:
- Frontal Theta power (4–8 Hz): associated with cognitive effort and memory encoding
- Alpha suppression (8–13 Hz): indicates active visual attention
- Frontal Alpha Asymmetry (FAA): left-frontal dominance correlates with approach motivation and stronger memory formation
The challenge is that EEG produces high-dimensional, noisy time series data. Turning that into something a classifier can use is non-trivial — and that's exactly where this project focused its energy.
Research Questions
This was my Master's thesis at Politecnico di Milano, supervised by Prof. Lucio Lamberti with co-supervision from Marc-Antoine Fortin. The core question I set out to answer:
How does the choice of EEG data representation influence the predictive effectiveness, computational cost, and practical applicability of machine learning models for advertising memorization?
Operationalized into two sub-questions:
RQ1 (Performance): Do temporal representation learning techniques (TS2Vec, FEMBA) outperform handcrafted spectral features in predicting unaided ad recall?
RQ2 (Efficiency): What is the trade-off between computational cost and predictive gains when using deep temporal embeddings versus static features?
These aren't just academic questions. For every data science team building marketing intelligence tools, these questions directly map to build-vs-buy decisions, infrastructure costs, and model explainability requirements.
Experiment
The data came from a controlled experiment at the BRIEL Lab (Behavioural Research in Immersive Environments Lab) at Politecnico di Milano:
- 300 participants, aged 18–80, recruited for demographic diversity
- Two TV viewing sessions each — editorial content interrupted by ad breaks (linear TV simulation)
- 13 advertisements from real brands in the Italian market (identities confidential per NDA)
- EEG recorded continuously using an 8-channel cap (international 10–20 placement) via the iMotions platform
- After each session: a structured questionnaire including unaided brand recall; the gold-standard outcome: "Name any brands you remember seeing."
The prediction target is binary: did the participant recall this brand spontaneously, or not? About 67% of observations are "recalled" — a mild class imbalance handled during modeling.
Analysis Methodology & Results
The full analytical pipeline follows four sequential stages designed for reproducibility and zero data leakage:
Stage 1 — Data Cleaning & Integration
Raw EEG and survey data needed significant engineering before any model could be trained. Key challenges and solutions:
Questionnaire data: Started with 1,195 records → filtered to 583 valid sessions after removing incomplete sessions, failed control questions, and data collection flags.
EEG missing data problem: The binned EEG data had 4.73% missing values, but critically ~90% of ad segments contained at least one missing time bin. Naively dropping rows would have destroyed temporal continuity.
The solution was a segment-aware imputation strategy:
- Compute the missing-value proportion per segment (not per row)
- Remove segments with >30% missing bins (unreliable)
- Apply linear interpolation within remaining segments — constrained by maximum gap length to prevent artificial trends
This recovered ~95% of missing data. Diagnostics showed ~88% of missing cases were isolated single bins, making interpolation appropriate for the vast majority.
Final aligned dataset: 2,835 advertisement-break-level observations after intersection of EEG and survey sources.
Leakage prevention: Used GroupShuffleSplit by participant ID — no participant appears in both train and test sets. This is the critical step that makes generalization claims valid.
Stage 2 — Feature Engineering & EEG Representations
This is the core methodological contribution. Three alternative representations of the same EEG data, with all non-EEG features held constant, to isolate the effect of representation choice.
Non-EEG features (identical across all representations):
- Ad position, duration, break length, session order, device type
- Composite perception indices: content quality score, ad perception score, brand influence — built from correlated questionnaire items via z-score normalization and mean aggregation
- Participant demographics (age group, gender)
- Prior exposure reconstruction — custom encoding scheme to handle a questionnaire design gap (participants not always asked this question)
EEG features — montage-level aggregations across frontal electrode regions (49 features):
- Attention Index, Engagement Index, plus Delta / Theta / Alpha / Beta / Gamma band PSDs. Z-score normalized per participant.
Three Ways to Represent a Brain Signal
This is the methodological core of the project. The same 2,835 observations were represented three different ways — everything else held constant to isolate the effect of representation choice.
① Classic Mean (Baseline) Average all 5-second EEG bins across the full ad duration → one vector per ad break. Fast, interpretable, directly tied to neurophysiological constructs. 145 total features.
② TS2Vec Embeddings TS2Vec uses unsupervised hierarchical contrastive learning. It learns timestamp-level representations by masking and cropping sequences, capturing local and contextual temporal dependencies. Mean pooling over the temporal dimension yields a 224-dim vector per ad break. Trained for 30 epochs.
③ FEMBA Embeddings FEMBA (Foundational EEG Mamba) leverages the Mamba architecture — a selective state-space model with linear-time complexity — trained via signal reconstruction. Designed for large-scale EEG processing. Same 224-dim output after temporal pooling. Substantially faster to run than TS2Vec.
Stage 3 — Model Selection
Model selection was conducted exclusively on the Classic Mean representation, with the test set held out throughout. Over 20 classifiers were evaluated across four families:
- Linear Models: Logistic Regression (L1, L2, ElasticNet), Linear SVM
- Tree-Based Models: Decision Tree, Random Forest, Balanced RF, Gradient Boosting, XGBoost, LightGBM, CatBoost, EasyEnsemble, AdaBoost
- Kernel & Distance-Based: RBF SVM, KNN
- Probabilistic & Neural: Naive Bayes, MLP
Top model candidates from baseline selection (validation set):
Given the class imbalance present in the data, models were ranked by ROC-AUC and PR-AUC rather than raw accuracy, with F1-score used as a secondary discriminator. This narrowed the field to two strong candidates: Gradient Boosting and Linear SVM.
To break the tie, a 10-fold group cross-validation (grouped by participant ID) was performed:
| Model | Metric | Mean | Std | 95% CI |
|---|---|---|---|---|
| Gradient Boosting | AUC | 0.880 | 0.022 | (0.867, 0.894) |
| F1 Score | 0.894 | 0.013 | (0.887, 0.902) | |
| Linear SVM | AUC | 0.876 | 0.026 | (0.860, 0.892) |
| F1 Score | 0.889 | 0.018 | (0.878, 0.900) |
While both models performed comparably, Gradient Boosting held a consistent edge across both metrics and exhibited lower variance — suggesting better generalization across participant groups.
Stage 4 — Comparative Evaluation
After fixing the classifier and the train/test split, the three EEG representations were evaluated on the held-out test set. Here's the full picture:
Note:
- Bold values indicate best performance per metric.
- Timing measurements were averaged across 10 runs conducted on the free-tier Google Colab environment.
Side-by-side bar chart comparing ROC-AUC and Recall for the three representations Grouped bar chart, two metric clusters:
Findings
1: The pipeline is the story, not the algorithm
All three representations substantially outperform the prior 70% accuracy benchmark. Hitting 83%+ accuracy and ROC-AUC ~0.90 across the board confirms the real value came from rigorous pipeline design — cleaning, feature engineering, leakage prevention — not from any single model choice.
2: handcrafted Mean wins on global discrimination
Despite being the simplest approach by a wide margin, Classic Mean achieves the highest ROC-AUC (0.8981). This is counterintuitive.
The implication: advertising memorability is primarily driven by sustained overall cognitive engagement — not just fine-grained moment-to-moment neural dynamics. Averaging over time doesn't erase the signal. Well-designed handcrafted features remain highly competitive in applied EEG classification.
3: TS2Vec wins where it matters for high-stakes decisions
TS2Vec achieves the highest Recall (0.9556) — meaning it misses fewer ads that will actually be remembered. In practical pre-launch testing, false negatives are costly (you reject an ad that would have performed well). If minimizing that risk is the priority, TS2Vec's +1.66pp Recall lift over Classic Mean is meaningful.
On the computational side, temporal models do require more training time, but total runtimes remain under 7 minutes, making the overhead negligible in practice.
4: Complexity is a strategic choice, not a default
All three representations achieve strong predictive performance which tells us something important in itself: aggregated brain signals already capture the core information driving memorization. Temporal models don't replace that signal; they build on it.
The meaningful difference lies in recall. TS2Vec achieves the highest recall, meaning it is better at detecting ads that will actually be remembered. In an advertising context, missing a winning ad is an opportunity cost — and that asymmetry matters.
Business Implications
Model metrics are meaningless to a CMO. The real question is: what is a recall lift worth in euros?
The incremental value of better ad selection can be expressed as:
Where is the improvement from traditional survey accuracy to EEG model recall , and is the return difference between a top-performing ad and an average one.
To make this tangible, consider three realistic campaign scenarios using the formula ΔP × ΔROAS × Budget, where ΔP is the recall lift over traditional methods (65% → 95.5%) and ΔROAS is the return gap between a top-performing and an average ad:
Even under conservative assumptions, better creative selection at the pre-testing stage generates six-figure incremental value on a standard campaign budget. At €9.6B industry-wide spend, the aggregate opportunity is substantial.
The practical workflow is straightforward: Test 3–4 creative variants on a small EEG sample before committing media budget, run them through the pipeline, and select the version with the highest predicted recall probability. The model is a laboratory pre-testing tool — once trained, inference takes fractions of a second.
Conclusion
The headline finding cuts against a common assumption in applied ML: that more complexity means better results.
A well-engineered simple model, built on a thoughtfully designed dataset, matched deep learning alternatives on the most important global metric — and did it in a fraction of the time.
That's not an argument against temporal embeddings. TS2Vec genuinely outperforms on recall, which matters when missing a winning ad carries real opportunity cost. The lesson is more precise: model complexity should be a deliberate choice calibrated to what you're optimizing for, not a reflexive default.
In advertising analytics — and in most applied ML — pipeline design, data quality, and a clear objective function matter more than algorithm choice. The right model is the one that matches your decision context. For high-stakes pre-launch selection, that means prioritizing recall. For interpretability and speed, the simpler model is not a compromise — it's the correct tool.
MSc Thesis in Management Engineering (Business Analytics) — Politecnico di Milano, A.Y. 2025–26
Other Projects
View all →
My website: A portfolio built with agentic AI tools
Built this portfolio as a website with agentic AI tools, using Codex, Claude, ChatGPT, Git, and Vercel instead of a no-code website builder.
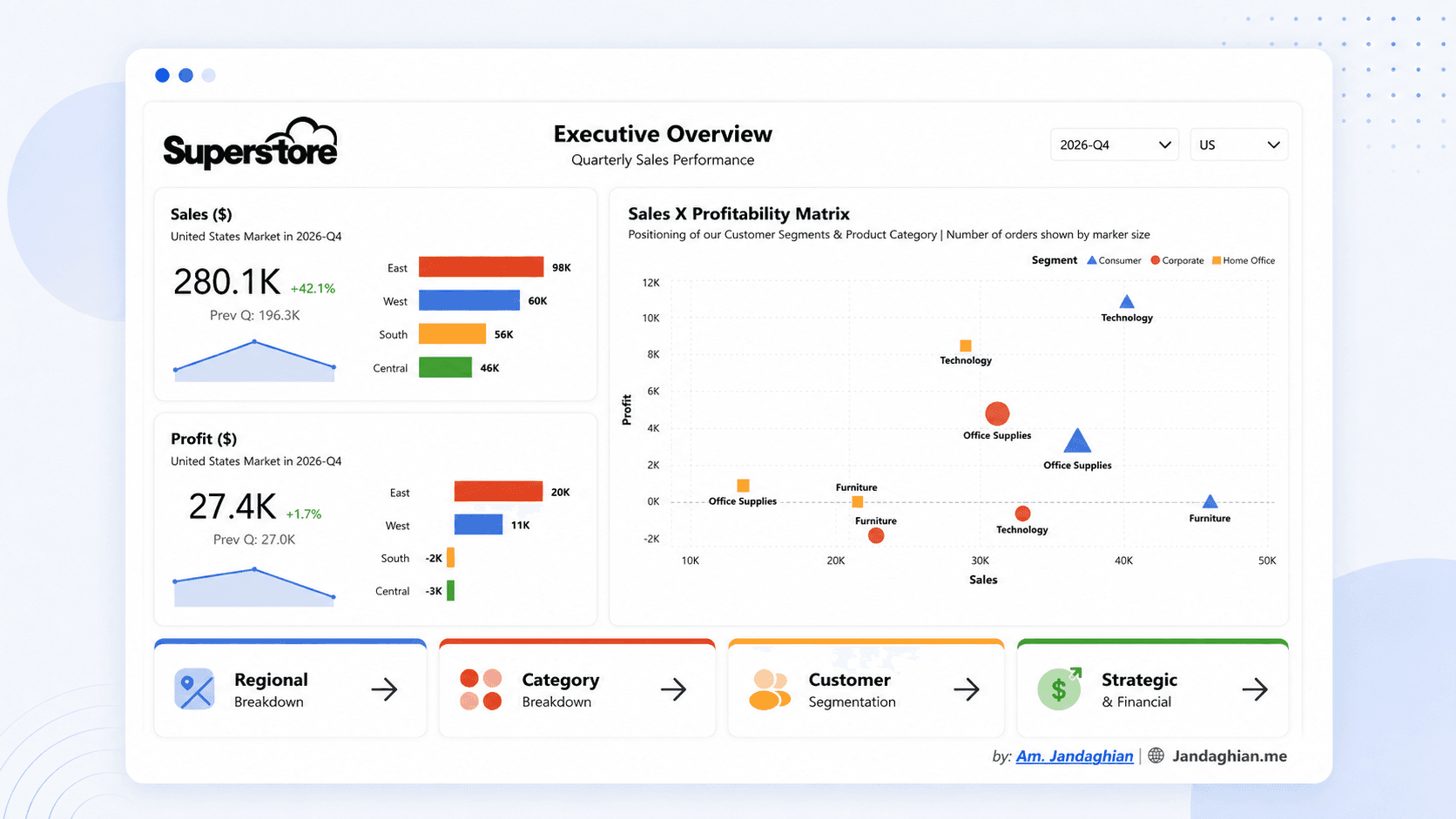
Superstore Sales Performance Dashboard
Built an executive Power BI dashboard on the Superstore dataset for quarterly sales, regional performance, categories, and customer segments.
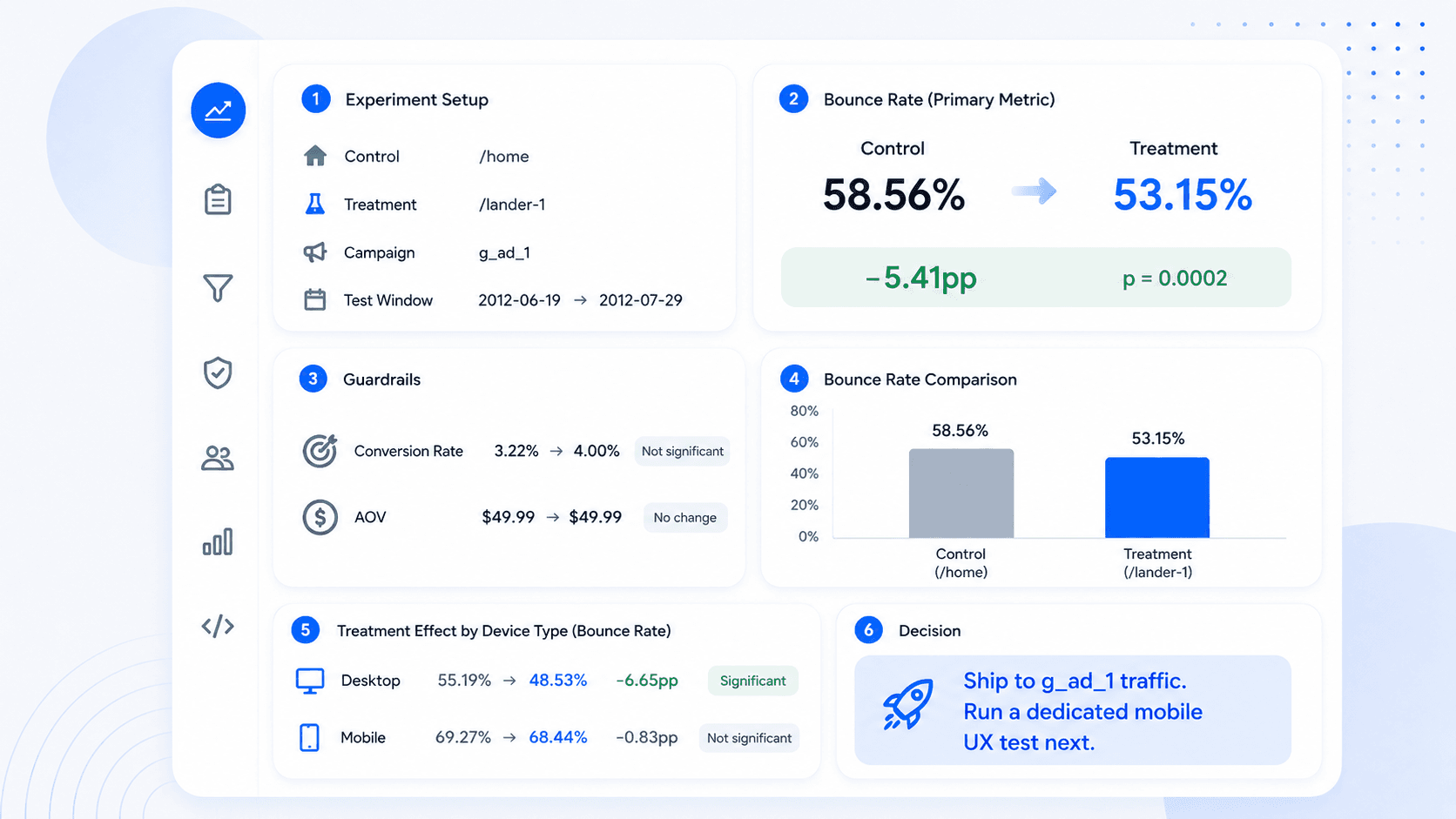
Maven Landing Page A/B Test Analysis
Analyzed a landing page experiment with traffic filtering, bounce-rate testing, guardrails, and treatment-effect cuts.
CONTACT
Want to compare notes on a project?
I'm always up for a sharp data or product conversation.
Get in touch